

Die Oracle Clusterware ist ein wichtiger Bestandteil der Oracle High Availability Architecture. Ressourcen, die unter Kontrolle der Clusterware stehen, werden überwacht, bei Systemstart automatisch hoch gefahren und nach einem Absturz neu gestartet oder auf einen anderen Server verschoben. Der Haupteinsatzzweck der Clusterware ist aber vor allem die Absicherung eines Serverausfalls.
Ein Cluster ist aufgrund seiner Komplexität anfälliger für Störungen in der Infrastruktur. Und eine der fatalsten Störungen ist der, auch nur vorübergehende, Ausfall des Netzwerk-Heartbeats zwischen den Clusterservern. In einem solchen Fall ist eine Kommunikation zwischen allen Clusterservern nicht mehr möglich und die Konsistenz des Clusters potentiell gefährdet. Wie die Oracle Clusterware darauf reagiert, ist insbesondere in Failover-Konstellationen von essentieller Bedeutung. Der heutige DBA-Tipp beschreibt, was du in diesem Umfeld beachten musst, damit dein High-Availability-Ansatz nicht „nach hinten losgeht“.
Ist die Kommunikation über das Interconnect-Netzwerk länger als 30 Sekunden gestört, geht die Clusterware von einem sogenannten Split-Brain-Szenario aus. Das heißt, der Cluster betrachtet sich als in zwei oder mehr Subcluster, sogenannte Cohorts, zerfallen, die nun zwangsläufig Gefahr laufen, ein „Eigenleben“ zu führen und damit die Konsistenz des Clusters insgesamt zu gefährden. Er reagiert darauf, indem er eine definierte Menge von Servern aus dem Cluster entfernt und sie erst wieder connecten lässt, wenn die Störung behoben ist. Dieses „Node Eviction“ genannte Verfahren wird durch einen Neustart des Clusterstacks auf den auszuschließenden Servern oder Reboot der betroffenen Server realisiert.
Da die beschriebene Node Eviction mindestens mit einem Neustart des gesamten Clusterstacks verbunden ist, bedeutet Node Eviction auch immer den Abbruch einer Untermenge der aktiven Datenbanksessions. Geht man jedoch davon aus, dass Clientsessions auf RAC-Datenbanken regelmäßig über alle Clusterserver verteilt sind, muss man sich hier keine Gedanken darüber machen, welche Server im Falle eines Split-Brain-Szenarios ausgeschlossen werden. Verhindern oder beeinflussen kann man es in diesem Fall sowieso nicht.
Anders sieht es hingegen bei Failover Ressourcen aus. Sie laufen normalerweise nur auf je einem Server des Clusters und damit ist ihr Placement durchaus relevant. Es wäre ja äußerst fatal, wenn im Falle eines Heartbeatausfalls – der für sich gesehen gar keine Auswirkung auf die Verfügbarkeit einer Datenbank hat – gerade der Server rebootet, der die produktive Datenbank betreibt, während ein Server mit Testdatenbanken oder gar ein leerer Standby überleben würde. Daher ist es wichtig, sich mit den Eviction-Regeln zu befassen.
Die primäre Regel des Eviction Algorithmus besagt, dass im Split-Brain-Fall der Subcluster überlebt, in dem die meisten Server verblieben sind. Der oder die Subcluster mit Serverminderheit werden ausgeschlossen. Lässt sich anhand dieser Regel keine eindeutige Entscheidung fällen, also mehr als ein Subcluster eine Servermajorität hat (im simpelsten Fall, einem 2‑Node-Cluster, enthält jeder der beiden Subcluster einen Server), greift die Eviction Regel II. Und für diese müssen wir wiederum vier Fälle unterscheiden, je nachdem, welche Version der Clusterware installiert ist. In der Grid Infrastructure Umgebung ermittelt ihr die Version eurer Clusterware mittels:
[oracle@c-tso-rac01(grid12c +ASM1) ~]$ crsctl query crs activeversion
Oracle Clusterware active version on the cluster is [12.1.0.2.0]
Bis einschließlich Clusterware Version 12.1.0.1 überlebt der Subcluster, in dem sich der Server mit der niedrigsten Nodenumber befindet. Diese Nodenumber wird fortlaufend an die Clusterserver vergeben und ergibt sich aus dem Zeitpunkt, zu dem der betreffende Server dem Cluster hinzugefügt wird – praktisch entspricht die Nodenumber also der Installationsreihenfolge, solange Server nicht aus dem Cluster gelöscht und später wieder hinzugefügt werden. Die Nodenumbers können in der Grid Infrastructure Umgebung ermittelt werden über:
[oracle@c-tso-rac01(grid12c +ASM1) ~]$ olsnodes -n
c-tso-rac01 1
c-tso-rac02 2
Eine nachträgliche Änderung der Nodenumber ist nur durch Entfernen und Wiedereinfügen des betreffenden Servers in den Cluster möglich. Solltet ihr also einen Cluster aus heterogen ausgestatteten Servern aufbauen, solltet ihr bereits die Installation der Clusterware entsprechend planen und die Server nach absteigender Wichtigkeit installieren. Bei homogen ausgestatteten Servern ist eine solche Überlegung nicht erforderlich. Einzige Ausnahme hiervon bildet ein Failover-Cluster, in dem von der 10-Tage-Regel Gebrauch gemacht werden soll. Hier muss zwingend und unveränderlich genau ein Standbyserver festgelegt werden, der dann auch nur vorübergehend Datenbanken betreiben darf. Für diese Rolle würde man folglich den Server mit der größten Nodenumber auswählen.
Gehen wir von obigem Beispiel, einem 2‑Node-Cluster aus den Servern c‑tso-rac01 und c‑tso-rac02 aus, wird im Fall eines Heartbeatausfalles immer der Server mit der Nodenumber 1, also c‑tso-rac01, überleben. Folglich sollten dort auch die wichtigeren Ressourcen platziert werden.
Andernfalls passiert folgendes:
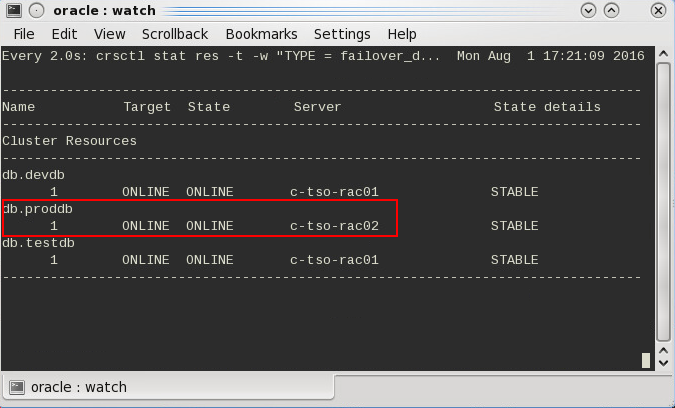
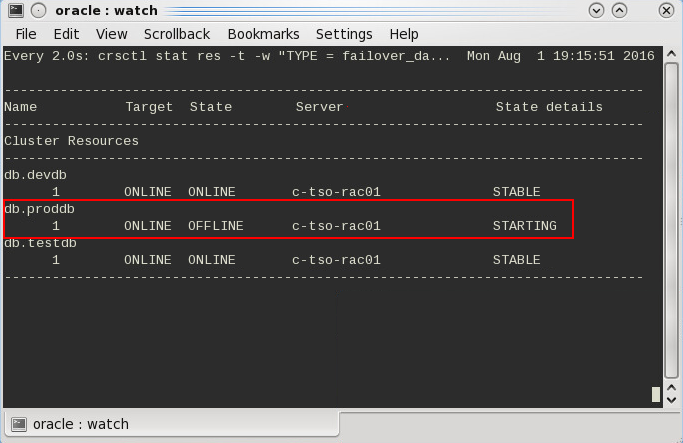
Das oben beschriebene Ausschlussverfahren lässt sich dann auch im ocssd.log der Clusterware nachverfolgen:
2016-08-01 19:16:19.943: [ CSSD][2446112512]clssnmCheckDskInfo: My cohort: 2
2016-08-01 19:16:19.943: [ CSSD][2446112512]clssnmCheckDskInfo: Surviving cohort: 1
2016-08-01 19:16:19.943: [ CSSD][2446112512](:CSSNM00008:)clssnmCheckDskInfo: Aborting local node to avoid splitbrain. Cohort of 1 nodes with leader 2, c-tso-rac02,
is smaller than cohort of 1 nodes led by node 1, c-tso-rac01, based on map type 2
Dieses Szenario liese sich beliebig oft wiederholen. Selbst wenn sich alle drei Datenbanken auf dem Node 2 befänden und der Node 1 damit quasi idle wäre, würde im Fall einer Heartbeatstörung der Node 2 aus dem Cluster ausgeschlossen und alle drei Datenbanken auf dem Node 1 neu gestartet.
In einem Cluster mit drei oder mehr Servern ist der Ausfall nicht so einfach vorhersehbar. Im ungünstigen Fall splittet sich hier vielleicht nur der Server 1 aufgrund eines NIC-Fehlers vom Cluster ab. Dann bilden die Nodes 2 und 3 den größeren Subcluster und 1 würde ausgeschlossen. Da aber eben genau das nicht vorhersehbar ist, ist man auch hier zumindest statistisch gesehen besser aufgestellt, wenn man die wichtigsten Ressourcen auf dem Server mit der niedrigsten Nodenumber platziert.
Das bis 12.1.0.1 implementierte Verhalten hat einen wesentlichen Vorteil – es ist zu einem großen Teil plan- und vorhersehbar. Insbesondere gilt das für einen 2‑Node-Cluster, einer der wahrscheinlich am häufigsten verwendeten Clusterinstallationen, zumindest im Standard-Edition-Umfeld.
Diese eben in Punkt 2 beschriebene, statische Evictionregel bis Version 12.1.0.1 hat jedoch gleichzeitig den Nachteil, dass sie keine Rücksicht auf die Anzahl der von den jeweiligen Servern bereitgestellten Ressourcen nimmt. Wie bereits in Punkt 2 erwähnt, würde unter Umständen auch ein vollkommen leerer Server zu Lasten eines Servers überleben, auf dem zahlreiche Datenbanken laufen. Vor allem im Hinblick auf den Cloud-Ansatz und policy-managed Clusterressourcen wurde Regel II mit Version 12.1.0.2 der Clusterware grundlegend verändert.
Der Ausschluss aus dem Cluster wird nicht mehr nur auf Basis der Nodenumber entschieden, sondern primär von der Anzahl der Datenbanken und Datenbankservices auf den infrage kommenden Servern abhängig gemacht. Es überlebt nun der Subcluster, auf dem in Summe mehr Services laufen. Leider zählen hierbei aber nur „echte“ RAC-Datenbanken und ‑services und die in 12.1.0.2 eingeführte Management Database mgmtdb, also Ressourcen vom Typ ora.database.type, ora.service.type und ora.mgmtdb.type. Failover-Datenbanken oder andere selbstdefinierte Clusterressourcen werden nicht in die Berechnung einbezogen.
Im Falle eines Gleichstandes der Anzahl Datenbanken und ‑services greift weiterhin die Eviction Regel IIa, d.h. der Subcluster, in dem die niedrigste Nodenumber vertreten ist, wird überleben.
Gehen wir davon aus, dass ihr einen reinen Failover-Cluster betreibt – also nicht auch noch RAC-Datenbanken vertreten sind – dann wird bei der Zählung der entscheidungsrelevanten Ressourcen also zwangsläufig nur die mgmtdb berücksichtigt. Folglich sollten alle wichtigen Datenbanken auf dem selben Node laufen, auf dem sich auch die mgmtdb befindet. Die Chance, dass diese ein split-brain-Szenario überleben, ist damit am höchsten.
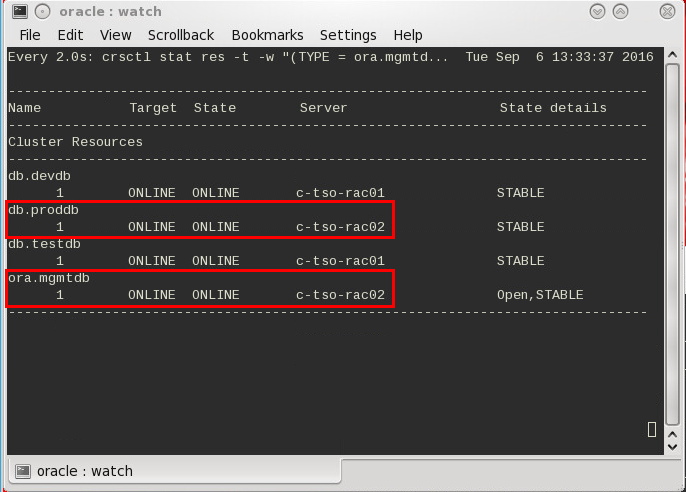
Um die Management Database (mgmtdb) auf den Clusternode mit der niedrigsten Nodenumber zu verschieben, setzt ihr in der Grid Infrastructre Umgebung folgenden Befehl ab:
srvctl relocate mgmtdb -node $(olsnodes -n|sort -nk2,2|head -1|awk '{print $1}') Das Verschieben der mgmtdb kann im laufenden Betrieb erfolgen und hat keine Auswirkungen auf die übrigen Clusterressourcen.
Möchtest du deine produktive(n) Datenbank(en) auf den selben Server wie die mgmtdb verschieben, tust du das mit:
rsctl relocate resource db.proddb -n $(srvctl status mgmtdb|grep 'is running on node'|awk 'NF>1{print $NF}') Das wäre aber mit einem Neustart der entsprechenden Datenbank verbunden, wenn sie nicht zufällig bereits auf dem richtigen Server liegt. Besser ist es daher, die Datenbank gleich auf dem richtigen Server zu starten:
crsctl start resource db.proddb -n $(srvctl status mgmtdb|grep 'is running on node'|awk 'NF>1{print $NF}') Falls du die betreffende Datenbank nicht verschieben kannst, weil dir kein Wartungsfenster zur Verfügung steht, kannst du aber zumindest noch die mgmtdb auf diesen Server verschieben und damit seine Überlebenswahrscheinlichkeit anheben:
srvctl relocate mgmtdb -node $(crsctl status resource db.proddb|grep '^STATE'|awk 'NF>1{print $NF}') In einem Failover-Cluster mit Nutzung der 10-Tage-Regel lässt du natürlich die mgmtdb nie auf dem Standbyserver laufen. Der Standbyserver sollte auch mit Clusterware 12.1.0.2 derjenige mit der höchsten Nodenumber sein.
Mit Clusterware 12.2 wurde die Gewichtung nach Datenbanken und Services aus 12.1.0.2 beibehalten, aber die mgmtdb wird nun nicht mehr berücksichtigt. Damit ist die mgmtdb nicht mehr als Token für die Festlegung des präferierten Servers nutzbar. Wir behelfen uns hier mit einer Datenbankinstanz „quorum“, die nur im nomount-Mode betrieben wird.
[oracle@c-tso-rac01 ~]$ echo -e \
"db_name=quorum\nsga_target=2G\nuse_large_pages=false" \
>$ORACLE_HOME/dbs/initquorum.ora
[oracle@c-tso-rac01 ~]$ export ORACLE_SID=quorum
[oracle@c-tso-rac01 ~]$ sqlplus -S / as sysdba <<sql
> create spfile='+DG_DATA/spfilequorum.ora' from pfile;
> sql
File created.
[oracle@c-tso-rac01 ~]$ srvctl add database \
-d quorum -o $ORACLE_HOME -p +DG_DATA/spfilequorum.ora \
-c single -x c-tso-rac02 -s nomount
[oracle@c-tso-rac01 ~]$ srvctl start database -d quorum
Ihre einzige Aufgabe ist es, als für die Eviction zählbare ora.database.type-Ressource zu fungieren. Sichtbar ist der Unterschied hier auch im Ressourcenname. Während die selbstdefinierten Failoverressourcen dem Namensschema db.<dbname> folgen, hat die quorum-Datenbank als „echte“ Clusterdatenbank das Namensschema ora.<dbname>.db. Diese Datenbank muss folglich auf der selben Seite wie die wichtigen Datenbanken laufen.
Ebenfalls mit 12.2 wurde an Clusterressourcen ein neues Flag – CSS_CRITICAL – eingeführt. Die Anzahl von Ressourcen, die dieses Flag auf yes gesetzt haben, fließt ebenfalls in die Gewichtung des jeweiligen Servers ein. Allerdings wurde dieses Flag nach unserer Erfahrung an selbstdefinierten Clusterressourcen nicht berücksichtigt. Eine Lösung hierfür konnte auch vom Oracle Support nicht bereitgestellt werden.
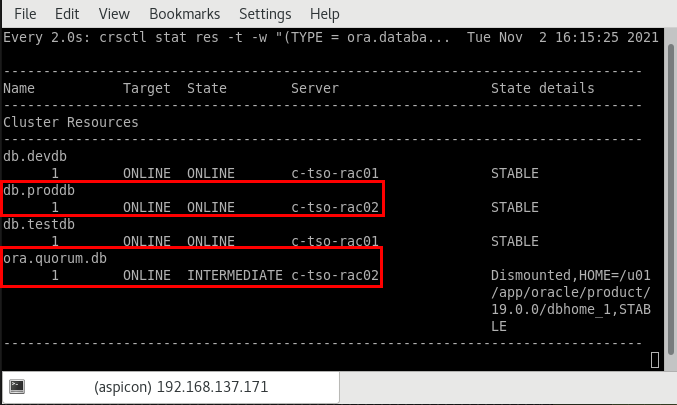
Mit Release Update 19.7 wurde das Konzept „Standard Edition High Availability“1 eingeführt. In seiner Wirkungsweise unterscheidet es sich nicht wesentlich von den bereits oben beschriebenen Failover-Datenbanken auf Basis selbstdefinierter Clusterressourcen. Drei wesentliche Verbesserungen gehen damit dennoch einher:
oracle@c-tso-rac01 ~]$ srvctl add database -db proddb \
-oraclehome $ORACLE_HOME -dbtype single \
-spfile +DG_DATA/PRODDB/PARAMETERFILE/spfile.383.1087569801 \
-node "c-tso-rac01,c-tso-rac02" \
-css_critical YES
[oracle@c-tso-rac01 ~]$ srvctl add database -db testdb \
-oraclehome $ORACLE_HOME -dbtype single \
-spfile SPFILE=+DG_DATA/TESTDB/PARAMETERFILE/spfile.294.1087569729 \
-node "c-tso-rac01,c-tso-rac02" \
-css_critical NO
[oracle@c-tso-rac01 ~]$ srvctl add database -db devdb \
-oraclehome $ORACLE_HOME -dbtype single \
-spfile +DG_DATA/DEVDB/PARAMETERFILE/spfile.295.1087574423 \
-node "c-tso-rac01,c-tso-rac02" \
-css_critical NO
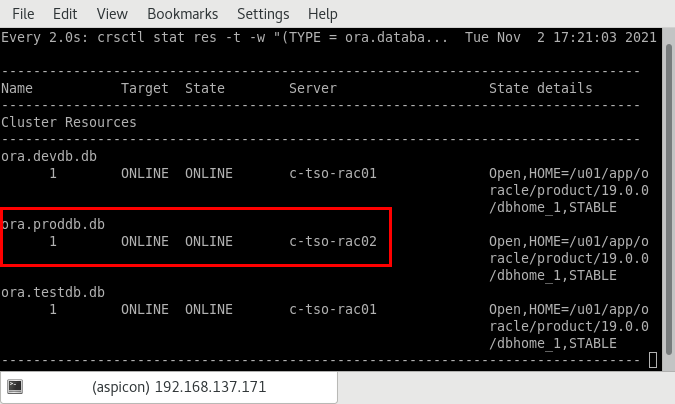
[oracle@c-tso-rac01 ~]$ srvctl start database -db testdb -node c-tso-rac01
[oracle@c-tso-rac01 ~]$ srvctl start database -db devdb -node c-tso-rac01
[oracle@c-tso-rac01 ~]$ srvctl start database -db proddb -node c-tso-rac02
Der Einsatz der Oracle Clusterware ist ein wichtiger Bestandteil einer zuverlässigen Hochverfügbarkeitslösung. Gleichzeitig handelt es sich dabei aber um ein komplexes Produkt, das insbesondere auf Störungen in seinen Kommunikationswegen empfindlich reagiert. Um die Auswirkungen dieser Störungen auf wichtige Ressourcen zu minimieren, müssen bei ihrer Platzierung nicht nur die Leistungsfähigkeit der Server berücksichtigt werden – sie sollte in Clustern ohnehin homogen sein – sondern auch die Auswirkungen einer möglichen Node Eviction.
Failoversysteme auf Oracle Clusterware sind am wenigsten wahrscheinlich von Node Evictions betroffen, wenn die wichtigen Ressourcen
Share this article